My post from the other day about slow instance starts on Azure caused some commentary (mainly on reddit) that prompted me to think more about all this. In the end, there were a few more experiments I wanted to run to see if I could squeeze more performance out of Azure.
First off, looking at the logs from my initial testing it looks like resource groups are slow. The original terraform creates a resource group as part of the test and then cleans it up at the end. What if instead we had a single permanent resource group and created instances within that?
Here is a series of instance starts and deletes using the terraform from the last post:
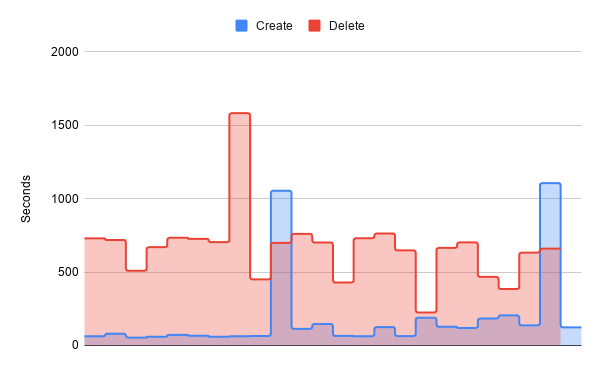
You’ll notice that there’s no delete value for the last instance. That’s because terraform crashed and never deleted the instance. You can also see that instance starts are somewhat consistent, except for being slower in the second half of the test than the first, and occasionally spiking out to very very slow. Oh, and deletes are almost always really slow.
What happens if we use a permanent resource group and network? This means that all the “instance start terraform” is doing is creating a network interface and then an instance which uses that network interface. It has to be faster, but does it resolve our issues?
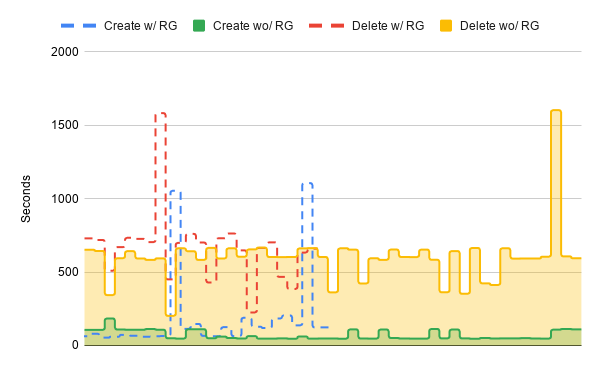
The dashed lines are the graph from above, the solid lines are the new data without resource group creation. You can see that abstracting away the resource group work has made a significant performance improvement. Instance start times are now generally under 100 seconds (which is still three times slower than AWS, and four or five times slower than Google).
So is it just that the Australian Azure zones are slow? I re-ran the new terraform against a US datacenter (East US). Here’s a zoom in of just the instance creates with the resource group extracted to make that clearer, for both data centers:
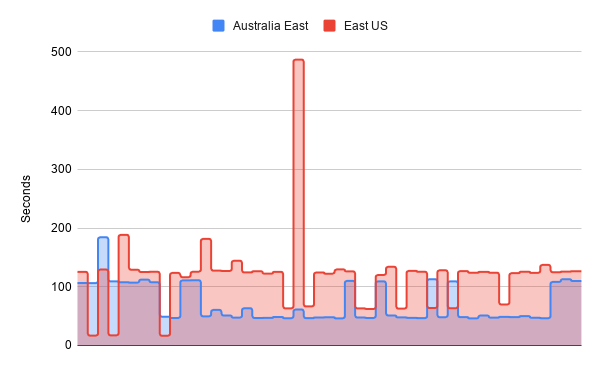
Interestingly, the Australian data center actually performs better than the US one, which isn’t what I would expect at all. You can also see in this test run that we do still see some unexpectedly slow instance launches, although they feel less frequent and smaller when they happen. That might also just be that I’m testing over a weekend and the data center might be more idle.
Looping back, I think we’ve learnt that resource groups are expensive. The last thing I wanted to dig into was what exactly was happening in those spikes where we had resource groups included. Luckily, they were happening about the point I started logging the terraform trace output of the run.
For example, run azure_1576926569_7_0_apply took 18 minutes and 3 seconds to create the instance. For those 18 minutes, terraform logs that the instance was marked by the Azure API as in provisioningState “Creating”. This correlates with operation id c983b272-fa32-4814-b858-adab3da4d9b1 sitting in state “InProgress”, unfortunately there isn’t a reason logged for why that is. So I guess its not possible as an Azure user to work out why things are sometimes slow.
To summarise some advice for terraform users on Azure — don’t create resource groups if you can avoid it. Create global resource groups and then place new objects into them instead. That said, you’re still going to have slower and less consistent performance than other clouds.
Finally, is instance start time a valid metric for cloud performance? Probably not. That said, it is table stakes to be in the conversation. Slow instance starts affect my overall experience of the cloud, as well as the workability of horizontal scaling techniques. This is especially true for instance start times which vary wildly like Azure’s do — I simply can’t trust that I can grow a horizontal scaling set with any sort of reasonable timeframe.