My primary personal project is a thing called Shaken Fist these days — it is an infrastructure as a service cloud akin to OpenStack Compute, but smaller and simpler. Shaken Fist doesn’t have an equivalent to the OpenStack Image service, instead letting your describe your instance images by a standard URL. One of the things Shaken Fist does to be easier to use is it maintains an official repository of common images, which allows users to refer to those images with a shorthand syntax instead of a complete URL. The images also contain small customizations (mainly including the Shaken Fist in-guest agent), which means I can’t just use the official upstream cloud images like OpenStack does.
The images were stored at DreamHost until this week, when a robot decided that they looked like offline backups, despite being served to the Internet via HTTP and being used regularly (although admittedly not frequently). DreamHost unilaterally decided to delete the web site, so now I am looking for new image hosting services, and thinking about better ways to build an image store.
(Oh, and recommending to anyone who asks that they consider using someone less capricious than DreamHost for their hosting needs).
All of this got me thinking. What would be the requirements for a next-generation image store for Shaken Fist? Given Shaken Fist is a personal project with not a lot of delivery pressure, I’ve been trying for the last year or two to “take the tangent” when one appears. In general I try to develop those ancillary things as separate sub-projects, in the hope that they’ll be useful to other people one day. Examples of tangents include Occystrap (OCI image support in python), and Clingwrap (a tool to build “field service dumps” of machine state to aid in debugging).
What would a better image store look like if I took that tangent? Here’s what I came up with:
- Efficient storage of images where the changes between the images are small: I do daily builds for the images, and theorize that therefore the images should be fairly similar day to day. It would be nice to only store the delta somehow when adding a new image.
- Improved cachability for clients: if they possess an older image which overlaps with a newer one, they should only have to download the delta.
- Support for cloud native object stores: there are a variety of inexpensive cloud object stores these days, and it would be nice to harness one of those for storage. The big limitation here is that in general these object stores do now allow for directory listing, so they’re good for key / value lookups where you already know the key, but not good for iterating all keys.
A specific non-goal is being fast to encode into the new format — that only happens once on a single build machine, and I am willing to accept some additional computation in return for reduced storage costs and faster downloads for my users.
My initial naive implementation uses the following algorithm:
- Split the file into chunks and calculate a sha512 checksum of that chunk.
- If the remote store already has a chunk with that checksum, do not upload.
- If it does not, then compress the chunk using gzip and upload it.
- Add the sha512 checksum to the list of chunks the file is composed of.
- After the entire file has been processed, emit a file containing metadata about the file, including the list of chunks.
My thinking is that the metadata file is the one you’d refer to when downloading an image, and the chunks would then be fetched as a second stage. I note that this approach has similarities to how Docker layers are stored in container image repositories.
There are some obvious experiments possible here. For example, what is the optimal chunk size? I should note that the chunk size can’t be too small, because each unique chunk becomes an object, and for some object stores (such as Linux filesystems), there are limits on the number of objects we can reasonably store.
I therefore took my 113gb collection of CentOS 8 images, and tried a variety of chunk sizes. I know I said above that I don’t particularly care about processing time, but I do think its good to keep track of. Therefore, I also measured the “no-write-IO” time to process the repository — that is I encoded the respository and then encoded it again to the same destination. This gives me a measure of processing time while not including any writes to the destination which hopefully minimises the noise from a busy spinning rust disk array as much as possible. Here are the numbers:
| Chunk size (mb) | Chunks | Repository size (gb) | Processing time (minutes, no writes) | Respository size (%age of original size) |
|---|---|---|---|---|
| 1 | 96,699 | 91 | 17 | 81% |
| 2 | 50,824 | 96 | 13 | 85% |
| 3 | 34,780 | 98 | 11 | 87% |
| 4 | 26,503 | 100 | 16 | 88% |
| 5 | 21,484 | 101 | 11 | 89% |
Or graphically:

But wait! The default in my previous image store used compressed qcow2 images — that is they have been compressed with the DEFLATE algorithm. These images are still sparse regardless of the compression used, so we are unlikely to see large blocks of zeros in the data.
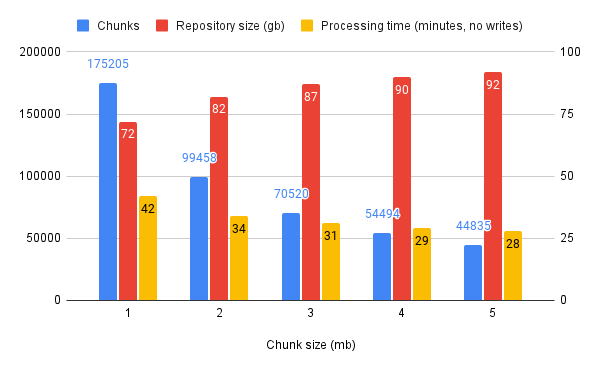
The compression in the source images means we’re trying to chunk up files with a streaming compression algorithm that likes to use references to previous data seen earlier in the file. It therefore seems likely that performance will change with uncompressed input images. Here’s the same experiment, but with 241gb of uncompressed images passed (the same images as before, just decompressed):
| Chunk size (mb) | Chunks | Repository size (gb) | Processing time (minutes, no writes) | Respository size (%age of original size) |
|---|---|---|---|---|
| 1 | 175205 | 72 | 42 | 64% |
| 2 | 99458 | 82 | 34 | 73% |
| 3 | 70520 | 87 | 31 | 77% |
| 4 | 54494 | 90 | 29 | 80% |
| 5 | 44835 | 92 | 28 | 81% |
Or graphically:
As an aside, there’s a notable flaw in this first chunking approach, because a change early in a file which offsets the chunks will result in each chunk being new. I haven’t thought of a computationally reasonable fix for that, so such is life for now. In theory, it could be fixed in this proposed format by inserting a small “shim” chunk which has that early change, but computing all possible hashes for all possible sliding blocks sounds super expensive to me. Rabin-Karp rolling hashes look promising for helping with this issue, but I haven’t persued it further because my target data is disk images which are block editted, not insertion editted.
So what option should I pick? My reading of the data is that there are sigificant server side storage wins (and an associated reduction in the need for client downloads) if I go for a smaller chunk size starting with uncompressed data, but I have concerns about the number of chunks a file download might incur — is downloading 1,024 1mb chunks actually faster than downloading a single 1gb file? I think that’s perhaps a matter for another post, as I’ll need to do some more benchmarking there.